I should be upfront that I might be biased about this. I do have a CS degree (Information Systems and Technology, which is close enough), but if I’m honest, I think I like biology more than I ever liked CS. I got into it through the biology olympiad in high school, then did a cell and molecular biology minor in college (and even did some wet lab work). In total, I probably took more than 50 ECTS of biology-related courses. These days, I work in biotech and many of my friends have a life science background. So when I have opinions about how biology should be taught to CS students, that’s the lens I’m looking through.
That said, I think I can still offer a perspective that’s a bit different. I have some sense of what CS people study, how they tend to see life science, and what might make biology click for them.
Anyway, let’s cut to the chase.
There was a course back at my university, roughly three ECTS, called “Domain-specific Computing.” It was meant to give CS students a bit of biology and a bit of bioinformatics. I never took it, since it only started the year after I would have taken it, but I’ve heard complaints about it from enough people. It opened with what was basically Biology 101, and then at the end, there was a bioinformatics project that didn’t directly connect to any of the biology that came before it. So the biology felt like something to just sit through, and the project felt tacked on just so the course could call itself “computational.”
Why it doesn’t land
Honestly, I think it should be quite obvious. If you front-load a bunch of terms before giving anyone a reason to care about them, most CS students will check out. Biology at the intro level looks like a list of names you just have to remember, pretty much the thing a lot of people went into CS to get away from.
Losing them for a semester is bad enough, but the part that really sticks is what they take away from it. A lot of people, CS students very much included, walk out convinced biology is memorisation. It isn’t. The facts are the foundation, the vocabulary you need before the rest makes sense, but they aren’t the real work.
And you can’t fully blame them, because this goes back to high school. Biology there is mostly taught as a bunch of facts to memorise for the exam, while subjects like physics at least get framed as problem-solving. By the time they’re choosing a major, they’ve already decided biology is the rote one. So the distaste isn’t really about your course at all. It starts in high school.
But that misconception hides what biology actually is. It’s really about working out how a system behaves and why, which is closer to reasoning than most people expect. We run experiments, we troubleshoot, we isolate phenomena, we build models. You can even reason your way to why some of the fundamentals are (probably) the way they are, though working that out from scratch isn’t practical for most people. Getting into the tidbits is hard, the same way the low-level core of CS like systems programming is harder than common web dev.
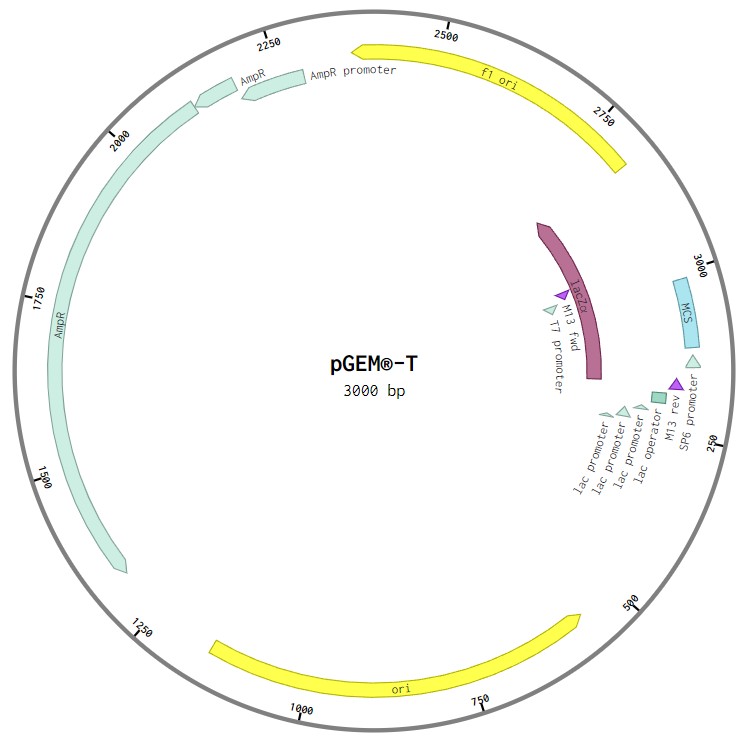
Figure: Illustration of the pGEM-T plasmid, along with the annotations for promoter, ori, selection marker, and other relevant parts.
In reality, those facts act more like a tool that lets us reason through things. Say you’ve engineered some bacteria to pump out a protein and the yield comes back near zero. You can’t just recall facts to fix it. You have to reason with what you know. Maybe the gene made it in but the promoter is too weak to drive much expression, so you check that first. Maybe the codons suit a different organism and the bacteria translate it slowly, so you might need codon optimisation. Or maybe the protein is folding into useless clumps, so you try growing the cells at a lower temperature. It’s reasoning all the way down. Even the plasmid in the figure above isn’t arbitrary, every part is chosen and placed deliberately to do its job.
Start from something they already understand
If it were up to me, I wouldn’t open with biology at all. I’d open with a problem the students can already get their teeth into, and let the biology come in later, only where it’s needed to make that problem make sense.
The good news is that a lot of bioinformatics turns out to be things they’ve already done. Comparing two DNA sequences is just the edit distance problem (remember Levenshtein distance?) solved with dynamic programming, and plenty of them will have coded it in an algorithms class without ever realising it could be applied to biology.
Heck, many modern bioinformatics analyses rely on cloud services, containerisation for reproducibility, HPC management, image analysis, and so on. Once they see that the tools are familiar, the biology can start to become the reason the problem is interesting in the first place. It’s like handing them a new playground.
The other entry point is the hardware. Strip a sequencer like ONT down to what it actually does and there’s barely any biology in sight: physical DNA molecule goes in, text comes out.
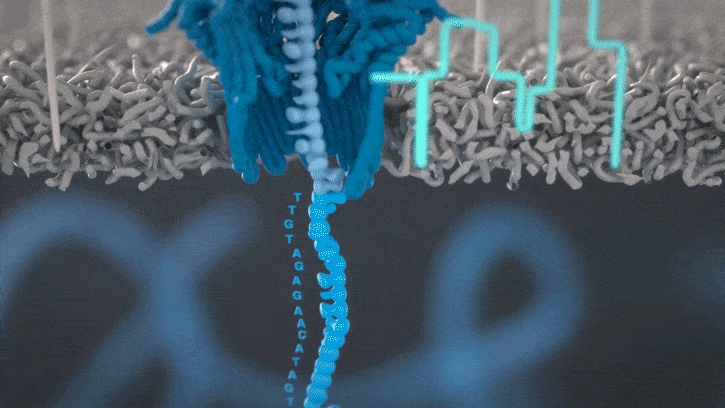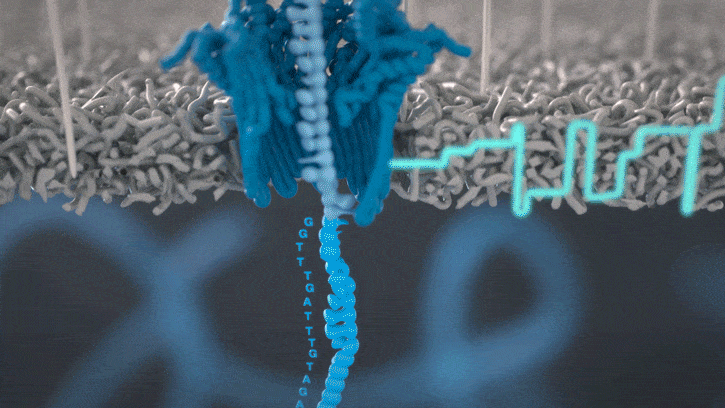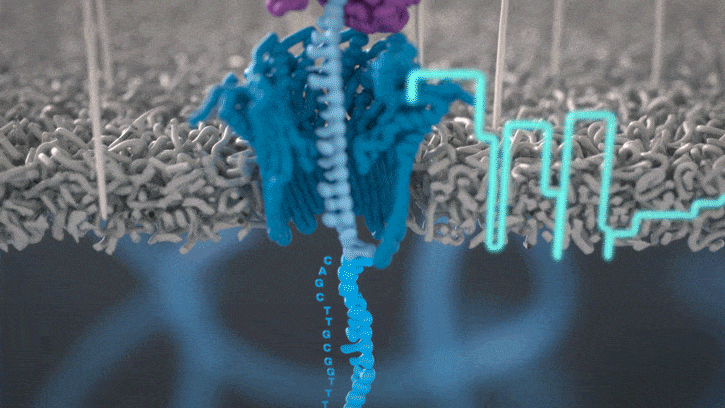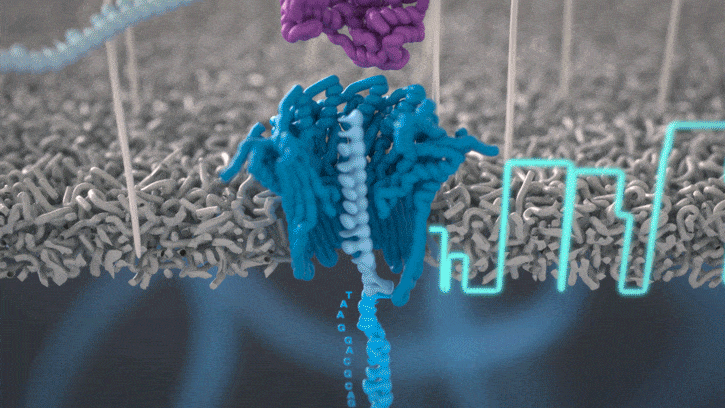
Figure: Illustration of a DNA strand disrupting current, which gets recorded as a signal by the ONT device. Source: Oxford Nanopore Technology (ONT).
In the ONT system, a strand of DNA threads through a tiny pore and disturbs an electrical current, and the sequencer samples that current a few thousand times a second. The basecaller takes that noisy trace and works out which bases (A/G/C/T) produced it.
The problem is that the signal doesn’t line up neatly with the bases. DNA moves through the pore at roughly 400 bases a second, and the motor enzyme pulling it through stutters instead of moving at a constant rate, so you can’t just slice the trace into even segments and read off one base each. You don’t know where one base ends and the next begins. About five bases also sit in the pore at any instant, so every measurement is a blur of its neighbours.
Framed that way, the history of basecallers reads like a tour of NLP. HMMs first, then RNNs and LSTMs to model the signal as a sequence, and now transformers for the high-accuracy models. They’re heavy enough to warrant a GPU. FYI, PromethION even ships with an A100 built in.
It also has to run live, since signal comes off the pore in real time and the basecaller can’t fall behind it. That constraint is what makes adaptive sampling possible: map the first second of a read against a reference, and if it isn’t a region you care about, flip the voltage and eject the strand to free the pore for the next one. Steering the machine from software like this can make sequencing cheaper for tests that only need a handful of sites. Read more about adaptive sampling here.
Looking at the data being produced, it’s just as familiar. It’s the big data problem. A single run can produce well over a terabyte of raw signal, so file formats start to become important. Nanopore started with FAST5, a custom schema on top of HDF5. Today it’s POD5, built on Apache Arrow, which reads into GPU memory with zero copies to avoid the I/O bottleneck.
Coming at it from this side will feel more familiar to them, and it also teaches them where their data came from and how far they can trust it.
The goal isn’t to produce bioinformaticians
The constraint that shapes all of this is how small the course is. At two SKS (roughly three ECTS), you’re not going to turn anyone into a bioinformatician. I don’t think you should even try. There isn’t enough time for that. Actual bioinformatics is a vast field with plenty of caveats and pitfalls, and it requires a ton of domain knowledge.
What you can do, and what I think the goal should be, is to widen their horizons. Show them that the thing they already know is useful somewhere they never thought to look. If a CS student walks out of that course thinking “Huh, I could see myself working on this,” then consider that a win. The field definitely needs good CS talent. There are tons of ways a CS person can help, even purely on the engineering side of things. That also settles how much biology they need, which is not much for this stage. What matters first is a rough feel for what DNA, RNA, and proteins are and how information flows between them. Then there’s the sequencing read, and knowing what it really is: a noisy guess at the true sequence. The last piece is a bit of suspicion, because biological data is full of effects that have nothing to do with biology, like samples run on different days or run using different kits.
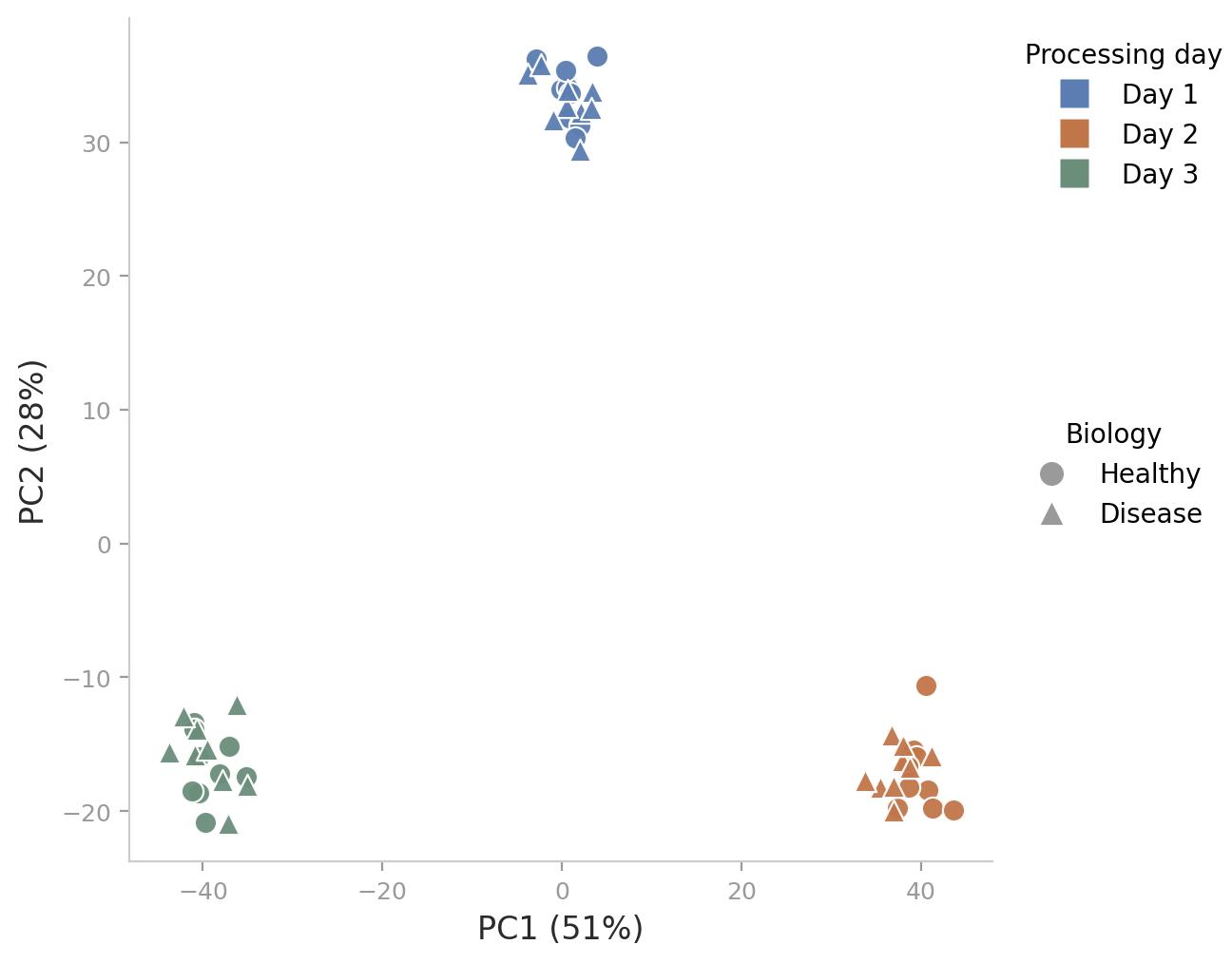
Figure: Illustration of the batch effect, something that CS students might want to know before using biological data in the future (e.g., ML thesis with clinical data).
And this cuts both ways. Just as a biologist learns to watch for things like batch effects, a CS person brings instincts a biologist often won’t have. Take a shell pipeline where you stitch together half a dozen tools. If one stage in the middle dies, the shell might still report success by default, leaving you with a number that looks reasonable but is fundamentally wrong. Or take an ML model that scores well. If the data was normalised before being split into training and test sets, the test set has already leaked into training. In fact, data leakage is a big issue in bioinformatics and cheminformatics. Those things might be second nature to a CS person, but they aren’t always obvious to a biologist.
Of course, becoming an actual bioinformatician eventually takes real domain expertise, but that can come later, and certainly not in a course like this.
Who should teach it
Whether any of this can actually happen comes down to whether there’s anyone capable of teaching it. You’d want someone who has really lived in both worlds, but they’re quite rare. The few who exist are usually off in industry, since universities (which tend to be quite siloed) prefer linear expertise anyway.
So in practice, you get a biologist or a CS person, and each runs into the same problem. A biologist will often stay glued to the fundamentals, perhaps because to them it all looks fundamental. Or they might be underestimating how fast a room of CS students can pick it up. As such, the course just never leaves 101. A CS lecturer hits the opposite wall. They often don’t know which parts of biology are interesting to tell, so they end up borrowing the intro slides from the biology department and reading them off, like someone singing a song they’ve never heard before at a karaoke bar.
To sum it up, I don’t have a clean solution here. I’m too biased to trust my own enthusiasm, but I’m quite sure about the direction. Open with a problem worth caring about, and bring in only the biology it needs.
Three ECTS won’t make a bioinformatician, but if it leaves a few CS students thinking biology might be a place their skills could go, that’s a good use of everyone’s time.